Introduction
We been testing AKS on Azure Stack HCI since Private Preview last year and are now running production workloads in a few on-prem clusters. During this time, we have tested new features as each new release pumps them out (we’ve also fell prey to some bugs, but thankfully the awesome PG team has saved our bacon each time).
The Problem
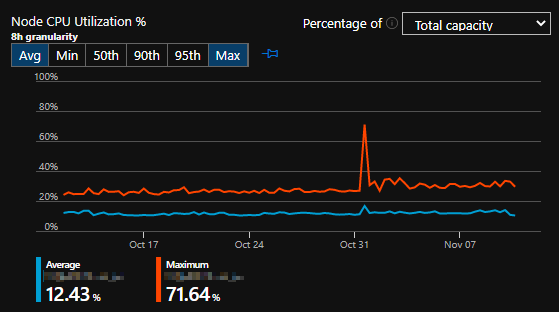
One of the challenges we faced early-on was deciding on the scale of our Linux worker node pool, specifically the count and size of VMs. We initially thought 4x VMs of size Standard_K8S3_v1 (4 vCPU, 6GB RAM) would be enough. However, as we deployed more and more releases, we realized that memory constraints started to crop up.
Currently, AKS on Azure Stack HCI does not support Vertical Scaling – the ability to modify your existing worker nodes size without adding more nodes to the pool. To get around our memory constraints, we were quickly went from 4x worker nodes to 7x! Considering AKS on Azure Stack HCI bills by vCPU count, we basically doubled our monthly cost for a resource (CPU) we didn’t even use!
And while you technically can hot-add RAM on the VM thru Hyper-V, don’t expect that to work well for a number of reasons:
- Kubelet doesn’t respect the balloon driver reporting new max memory without a service restart, so pod scheduling and metrics will be wrong.
- AKS on Azure Stack HCI health checks will routinely inspect a VM’s configured state against desired state. If there’s a mismatch, it’ll destroy and recreate the VM back the the “expected” state – in our example, the lower memory.
So how do we migrate an existing workload gracefully to the correct VM size without having to create a new AKS on Azure Stack HCI cluster… and also do it with basically zero downtime?
The Solution
Simply put – we will be creating a new node pool and forcing all the existing pods over to it. Our application release process is pretty basic. We don’t use taints, labels, etc for our deployments, so the steps to migrate are simple:
- Cordon the old nodes in the Linux node pool
- Create the new Linux node pool
- Drain the old nodes in the Linux node pool one-by-one
- Delete the old Linux node pool
If you only have a single k8s cluster deployed, some of these steps will be redundant. But in the event you have multiple clusters, this should help you determine exactly what you need to update.
Step 0
Cordon off your existing Linux worker nodes with kubectl. We’re doing this to make sure no new pods are scheduled on these nodes while we perform the following steps. Depending on how active your environment is, someone or something may kick off a release pipeline that will throw a wrench into your work.
This can be done by running kubectl get nodes, copying all the hostnames of the Linux nodes, and then running kubectl cordon xxxx,yyyy,zzzz (where xxxx, yyyy, zzzz are the hostname strings).
Identifying the Linux worker nodes with AKS on Azure Stack HCI is easy… the name will start with moc-l (that’s a lowercase L) and the roles will be <none>:

Step 1
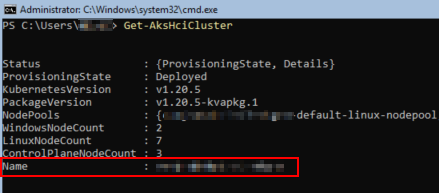
Next we need the AKS on Azure Stack HCI cluster name. If you don’t know it, you can find it easily with Get-AksHciCluster
Step 2
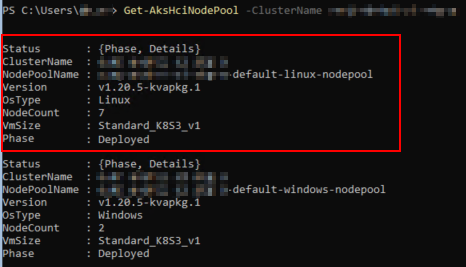
Now we need the Node Pools, which you find with Get-AksHciNodePool -ClusterName <aksClusterName>
Step 3
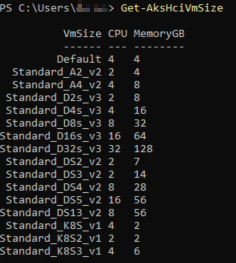
The Node Pool we are updating currently has 7 nodes and is VM Size Standard_K8S3_v1, which is 4vCPU and 6GB RAM. If you’re curious about what other VM Sizes are available thru AKS on Azure Stack HCI, you can run the Get-AksHciVmSize command:
Step 4
For my new Node Pool, I want to have 4x Linux VMs and a size that has 4 vCPU and 16GB of RAM. Looking at the screenshot above, that matches to Standard_D4s_v3
Before we create the Node Pool, make sure you actually have enough free RAM on the Hyper-V hosts for the VMs you’re about to make. If you don’t, you’re gonna have to scale back your existing Node Pool or do some other black magic to make this happen.
(As a rule of thumb, you should always leave about half your memory free so AKS on Azure Stack HCI rolling updates can take place, so this shouldn’t be an issue 😜)
To actually create the new Node Pool, we need a name for it that is alphanumeric and all-lowercase. I went with <aksClusterName>-default-linux-nodepool-16gb (which is the same as the original one, other than the fact that I appended -16gb to the end.
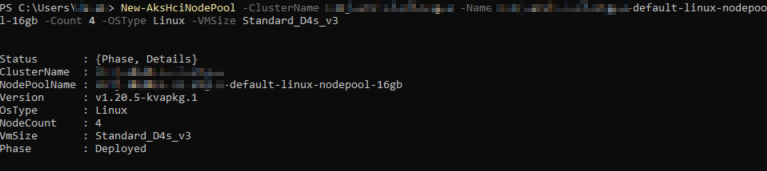
The full command to run is New-AksHciNodePool -ClusterName myCluster -Name myCluster-default-linux-nodepool-16gb -Count 4 -OSType Linux -VMSize Standard_D4s_v3
This may take a few moments to complete; AKS on Azure Stack HCI will download the latest Mariner OS image over the internet to deploy these new nodes. Once completed, the output should look like this below:
Step 5
The next few steps are overkill – we’ll be draining the cordoned nodes one-by-one to move the workloads off. In reality, unregistering worker nodes from Kubernetes can do this for us, but this will demonstrate that the new Node Pool is working correctly and you can schedule pods to it. Remember – my environment does not use deployments that use labels, taints, or anything advanced. If you need to configure those, do it now!
To evict the old nodes, we will once again use kubectl. When you run kubectl get nodes -o wide, you’ll notice your list of VMs has grown and there will be differences in their AGE (and maybe KERNEL-VERSION and CONTAINER-RUNTIME). Make note of which nodes are older because those will be the ones you are going to drain:

One-at-a-time, run the following command and watch your pods get evicted successfully:
kubectl drain <node> --ignore-daemonsets --delete-local-data
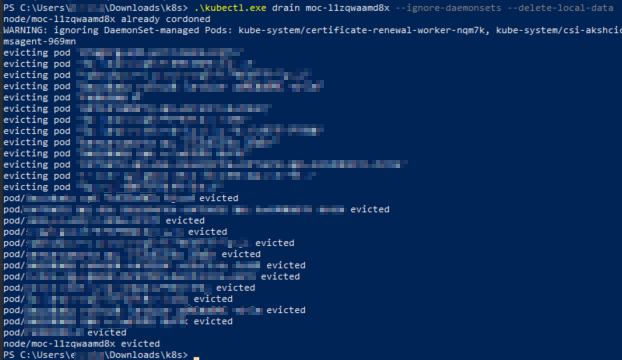
Confirm your apps are still running. If everything is good, repeat kubectl drain for the remaining old nodes.
Step 6
When all your worker nodes have been drained, you can now begin the process of deleting the old node pool. This will complete fairly quickly as all it does is unregisters the nodes from the Kubernetes cluster, turns off the VMs, and deletes the VM and files.
To do this, run Remove-AksHciNodePool -ClusterName myCluster -name myCluster-default-linux-nodepool and make sure you specify the old node pool name! You don’t want to fat-finger this and blow away your new node pool!
Warning: Do not manually delete the nodes using kubectl delete – you must use the Remove-AksHciNodePool command to make sure everything is cleaned up and your cluster is in the correct state!

Step 7
At this point, everything should have been deleted and you can confirm Hyper-V and Kubernetes only sees the the expected VMs:

Closing Remarks
Depending on your environment (how often deployments are made, etc), you could probably get away with 2x steps – creating the new node pool and removing the old one (you can probably skip the cordon and drain steps). Kubernetes does a pretty good job at handling pod placement as things are spun up and spun down – it is a container orchestrator after all! I have not personally tested this more “aggressive” approach, but if you are feeling frisky, give it a try and leave a comment below with your results!