I recently had to scale a 2-node Azure Stack HCI 21H2 cluster out to 4-nodes. This is a relatively painless process if:
- You previously registered your HCI cluster using a Service Principal
- You have a repeatable and automated way of configuring your network and storage settings
One day, I will write another post and go into more detail about those bullet points (spoiler alert: it involves Network ATC). But for all intents and purposes, all you should need to do is run Add-ClusterNode -Cluster "clustername.contoso.com" -Node "newnode.contoso.com"
That was not the case for me. Upon adding the nodes, Azure Portal showed the new server in the list, but in an Not Installed state for Azure Arc. Huh!?

My immediate thought was because I didn’t register the Cluster originally using a Service Principal. I had registered it using my Azure AD user and a DeviceLogin key. So I attempted to re-register the entire cluster and specify the new node specifically:

This “succeeded”, but didn’t actually improve the Arc situation in Portal. The node still said “not installed”.
I bounced a few ideas off of Jaromir Kaspar, a great friend of mine, and he reminded me that “Arc installation is a Clustered Schedule Task”. In case you didn’t know that was a thing, here’s a snip of the actual script the Task runs:
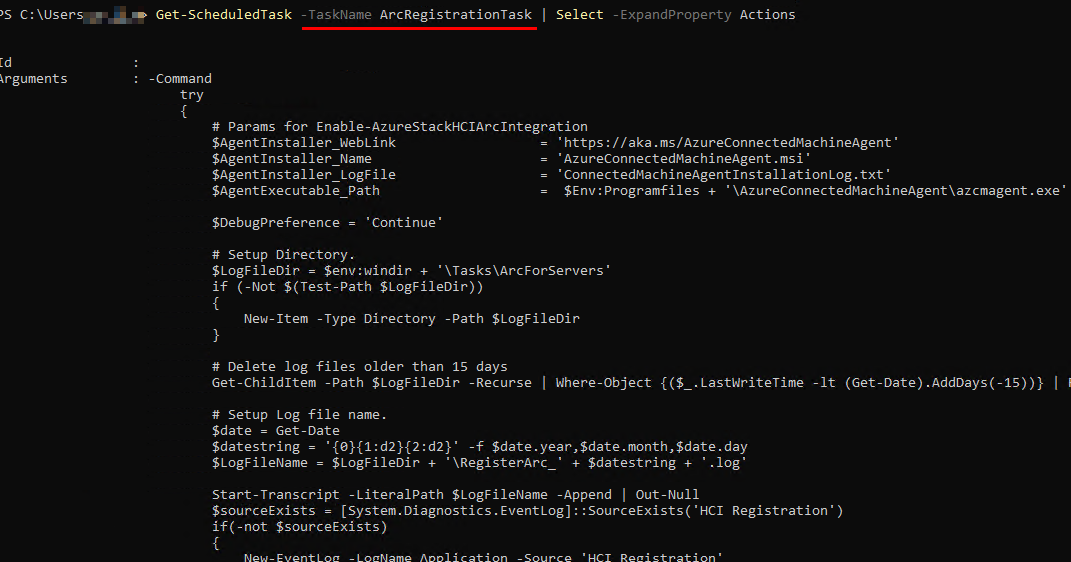
Cool, so this Powershell script should run every day and attempt to install the Arc Agent if not installed. Let’s assume it is installed and can check WTF is going on by running azcmagent show
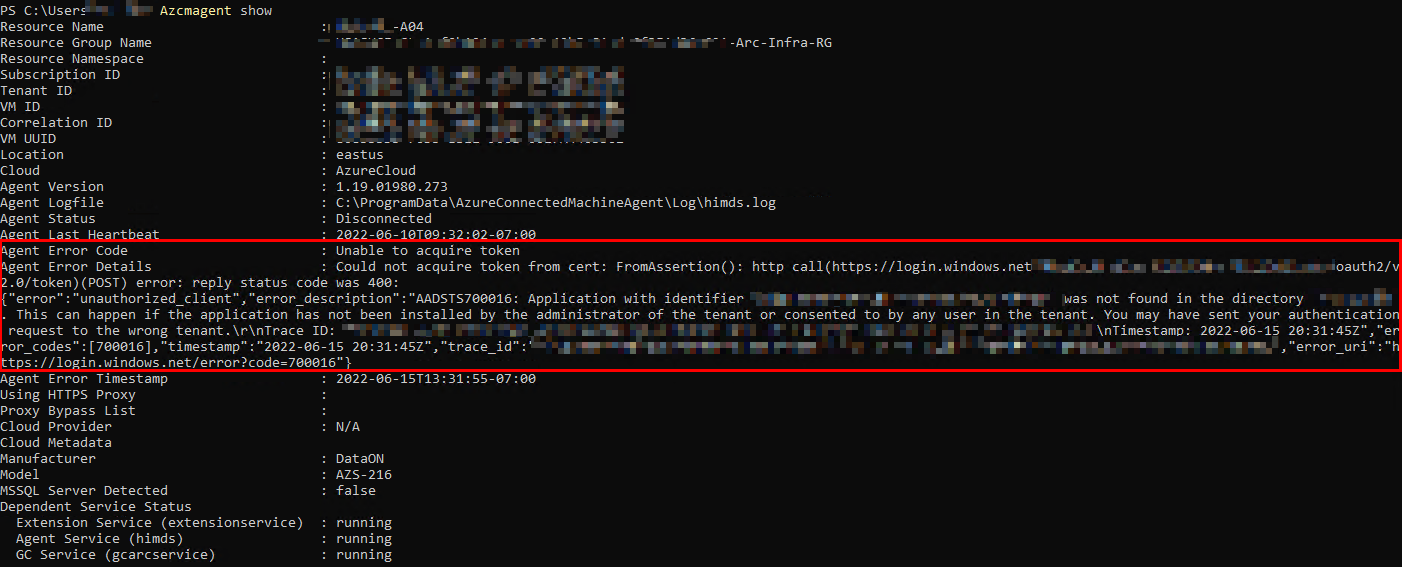
OK, now we are getting somewhere! This definitely feels like something borked up because of the way the cluster was originally registered. I don’t feel like blowing the entire thing away right now and re-registering it with a Service Principal, so let’s check one more place for Arc status:

The plot thickens! It appears the node itself thinks it is Arc-enabled, but obviously Portal and other logs tell a different story. This is an easy fix – disable and reenable:
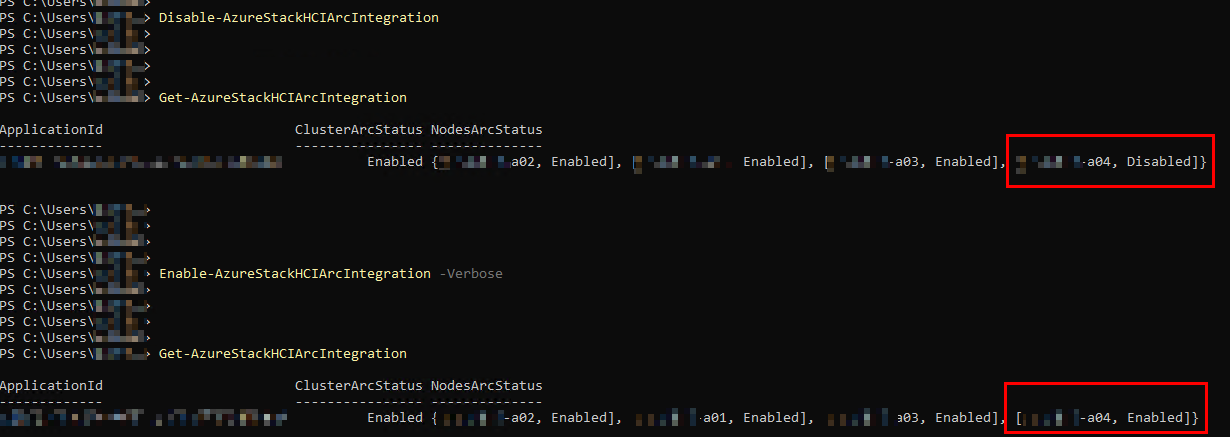
Boom! And let’s refresh Azure Portal:
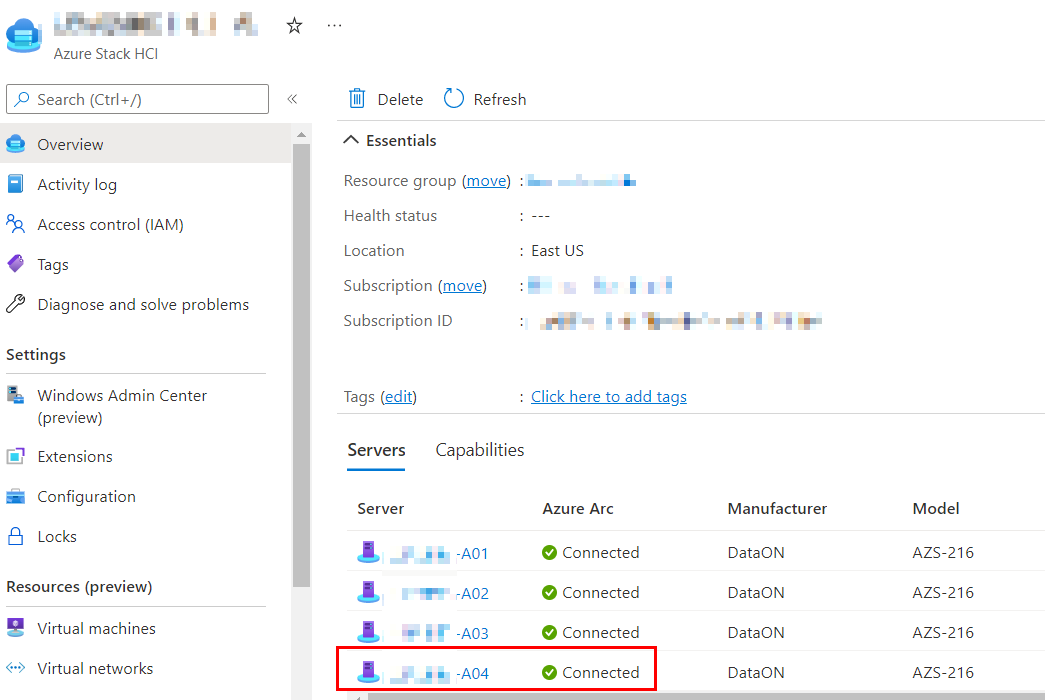
Bingo! Everything is kosher. Even azcmagent show is happy again:
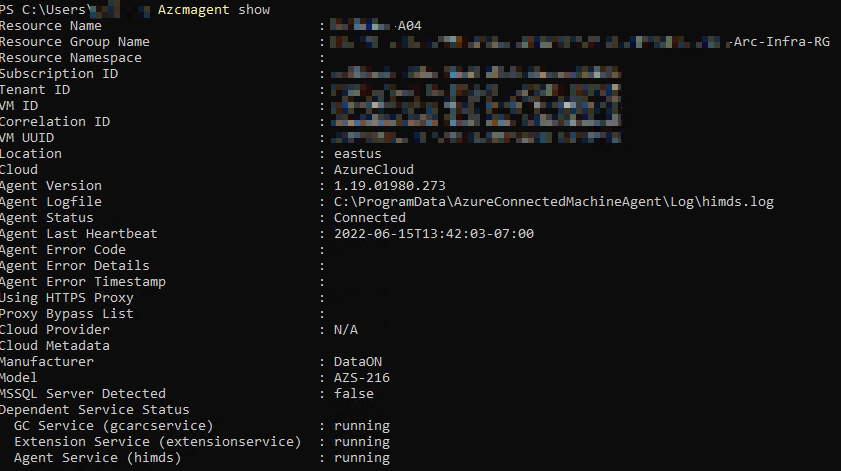
The good thing is during this entire ordeal, my cluster was fully usable from a Storage and VM perspective. S2D was happily doing its thing in the background, optimizing the Storage Pool. The impact was minimal, but do not let your cluster stay in this state for too long or you can have it go into an unhealthy state where VMs will not start up on the “bad” node.