tl;dr – The Quick Fix
Despite what the error message may say, there is no scan actually in progress. Instead, you need to clear some bogus Dirty Region Tracking (DRT) flag by kicking off a Data Integrity Scan for Crash Recovery on the owning node of the CSV:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask

The job may take awhile to complete; you can track it’s status by checking if the Task is still running (State -eq “Running”) or on the node’s Event Logs.
WTF is Going On?!
When some of our Hyper-V servers were BSOD’d due to CrowdStrike, we noticed that we were unable to pause/drain cluster nodes because of a CSV migration error:
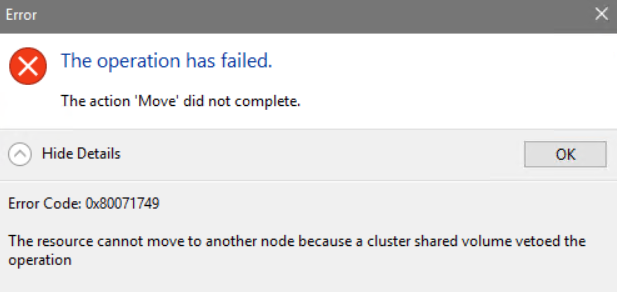
Error Code: 0x80071749
The resource cannot move to another node because a cluster shared volume vetoed the operationMove of the Cluster Shared Volume resource 'Cluster Virtual Disk XXXX (XXX)' is vetoed because there is a Data Integrity Scan is in progress on one of the volumes belonging to the resource. Please retry the action after the operation is completed.Yes, that poor grammar is the actual message; see screenshot below.


Microsoft has documented steps on when to leverage Data Integrity Scans to alleviate possible S2D issues if you have some kind of catastrophic hardware issue. However, I was not having these problems. My Virtual Disks are healthy, my CSVs are online, and my data is functional – I simply cannot migrate the CSV to another node, interrupting my reboot or patching process.
After working with MSFT Support, they suggested I go ahead and run this Scheduled Task on the “bad node” anyway. To my shock, things started to happen!
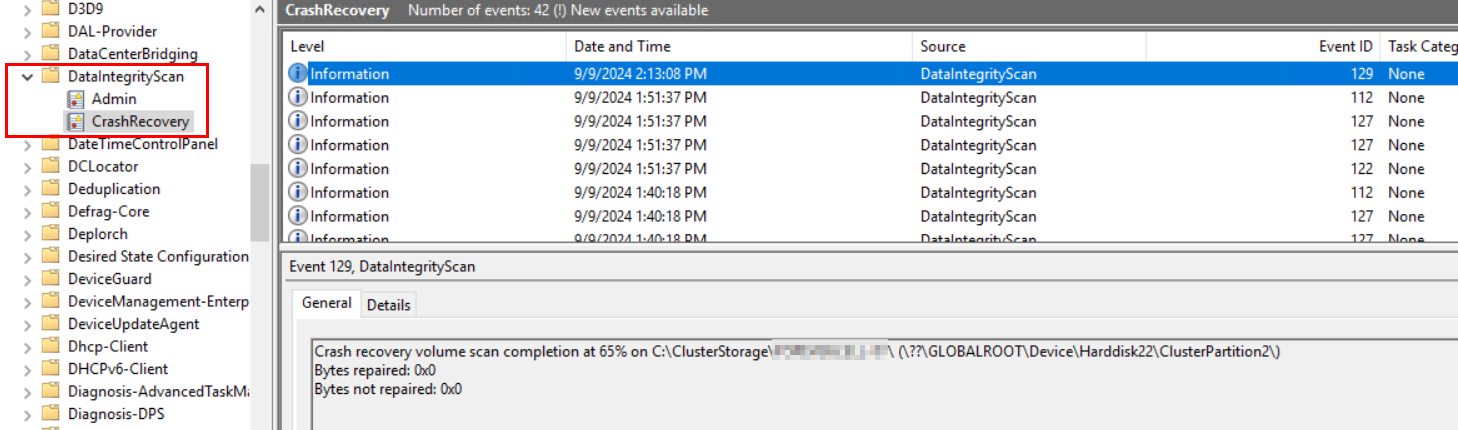
In my situation, I had 4x CSV that were “stuck”. The first 3x CSVs completed their scans in about 10 minutes. The final CSV took over an hour. My system is all-NVMe, so if you have spinning rust or SATA/SAS drives, expect this to take longer.
When it was completed, this was the logged Events:




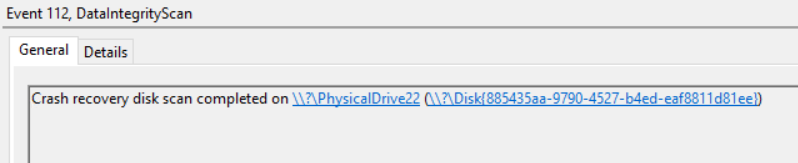
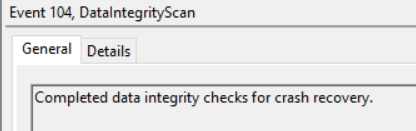
And as expected, I could move my CSV’s to another node and move on with my life 😛
Thanks, this helped with our problem.